Diving into an Agentic AI Taxonomy: A Zero Trust Perspective (part 1)

Posted: Thursday May 21, 2026
Author: Jason Garbis
Our first analysis of Agentic AI systems, using the Agentic Trust Framework
This is a big topic, one that I’ve frankly gone back and forth about while writing this article. “This could be an entire book,” I thought more than once while drafting and writing, but I really wanted to get these thoughts out there pronto, and get feedback from enterprise security practitioners on their utility and accuracy. And, we of course fully expect things to continue to evolve. This technology area is so fast-moving that we need this kind of shorter-form articles to try to keep up.
Recall, in our earlier blog on “Agentic AI: The Wild Frontier”, we introduced a simple Agentic AI taxonomy, which is shown below:

We created this because we needed a useful but simple way of organizing things, and the existing Agentic AI taxonomies we found were too complex or otherwise inappropriate for our purposes. So, we created this map, and like all maps it has some oversimplifications. For example, it’s absolutely the case that many AI platforms, vendors, and agent frameworks, won’t fit neatly into this nice clean taxonomy. That’s okay; this structure will still prove useful to organize our thinking as we proceed through this series of articles.
Why This Series?
Looking back, I’ve had a lot of conversations with information security professionals in the past couple months about Agentic AI, and how we should apply Zero Trust principles to this. Agentic AI adoption raises an important, urgent, and necessary set of challenges that we have to face, while we’re living through what is inarguably a chaotic time in information technology and security. In particular, even while security teams and leaders are worried about (and potentially distracted by) the growing volume and accelerating speed of vulnerabilities and exploits, we also have an imperative to support and enable secure adoption of AI by the business.
In fact, “enabling the business” is something that we’ve been saying for so long in infosec that it risks losing its meaning, like any phrase that is repeated too often. We need to take a step back and recognize that generative AI is the best example of business-driven technology adoption in recent memory, and it’s imperative for us as security professionals to securely enable its usage by the business. In fact, opposing or resisting AI usage is likely to be a recipe for infosec marginalization (or worse).
The good news is that across all my conversations with security leaders, they universally recognize this, and they and their teams are active participants in what’s often organized as an AI Center of Excellence or a Tiger Team within their enterprise. This led us to start putting together this series of blog posts.
We recognize that there’s a need for a model to give us a structured way to think about the security capabilities that we need to secure agentic AI systems. More importantly, we need to put these in the right context, because (and we should feel some relief about this), we don’t need to solve every problem for every AI agent.
Finally, it’s also important to acknowledge that securing Agentic AI is new to everyone. This space is moving very quickly, so encourage your team to stick with it, and be prepared to iterate. We’re continually learning right along with you.
Diving In
We’re going to start our analysis with the simplest type of agents, which are general-purpose web-based agents operated by AI providers. Specifically, right now we’re limiting the discussion in this article to browser access to general-purpose cloud-based agents, such as Claude, ChatGPT or Microsoft’s simple Copilot version, among many others. We’re deliberately limiting this initial scope to just browser or app-based interaction with these agents, where users interact with them by typing prompts, copying and pasting inputs and outputs, and uploading files. Note that variants of these platforms where users install and run code on their device, or M365-based Copilot will be covered in future articles.
We’ll be taking a structured approach to this analysis, using the Agentic Trust Framework (ATF) with some very slight tweaks to better align it with our purposes here. If you’re not familiar with the Agentic Trust Framework, it’s an open source model and is a simple but powerful way of analyzing AI systems. They define it as Zero Trust Governance for Autonomous AI Agents, and provides a progressive system of agentic autonomy.
The Agentic Trust Framework

Source: https://github.com/massivescale-ai/agentic-trust-framework
We’re taking some slight artistic liberties with the model here, as the AI agents to which we’re initially applying it are not, in fact, autonomous, and we’ve tweaked the questions slightly to better suit our purposes. But we’re confident that the team at MassiveScale.ai, the creators of the Agentic Trust Framework, will forgive us.
So let’s analyze this first simple set of agents from this perspective. The ATF poses questions across 5 areas, and we’ve provided answers and analysis for each in the table below. Remember, we’re performing this analysis on simple web-based general-purpose agents, such as Claude, ChatGPT, or Google Gemini.
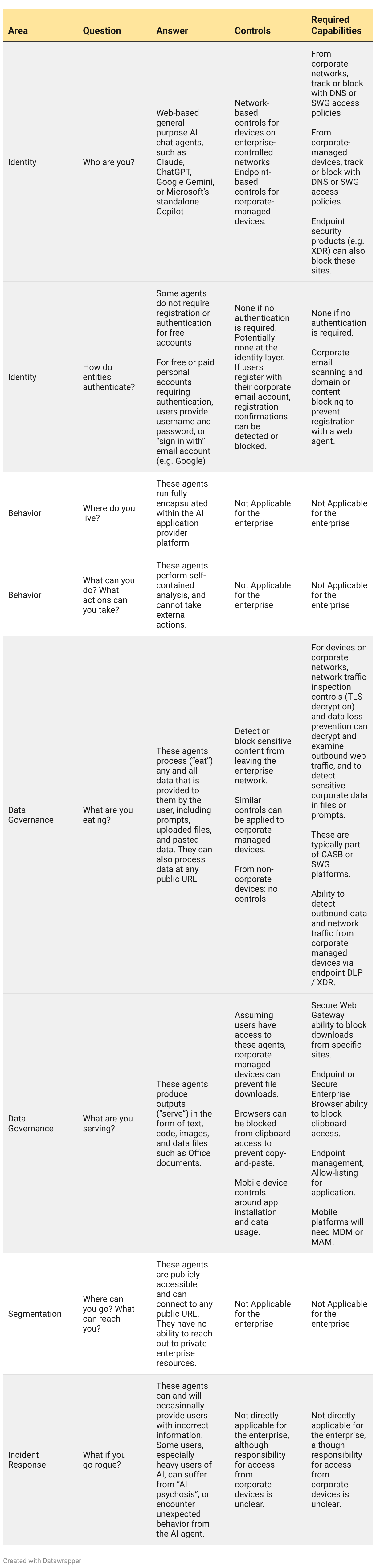
Zero Trust Principles: Commentary and Recommendations
There’s a lot to that table, so I want to summarize and present a set of recommendations (and some considerations).
Recommendation 1: Visibility
First, remember that Zero Trust doesn’t mean “zero access,” but security leaders do need to recognize that they have a responsibility to obtain visibility into what’s occurring on their enterprise’s networks and devices. So visibility is a big and important first step. Yes, there is an ever-changing set of web-based AI systems that users can access, but that shouldn’t be an excuse not to track where users are going, even if it’s imperfect.
Recommendation 2: User Education, and User Listening
Because this is such a new and rapidly evolving area, it’s imperative that security leaders regularly communicate with users in their enterprise. This message, of course, needs to align with the overall corporate strategy on AI adoption, but at its core should be oriented around a “here’s how to use AI safely” message, rather than “don’t use AI.”
The education should include a reminder of data security requirements and responsibilities, as well as a basic primer on AI architectures so that people understand what’s actually happening to the files and data they send to their favorite AI agent.
And, this interaction also needs to include some deliberate time for your security team to listen to how users are using (or want to use) AI. You’ll learn a lot about the needs of your business users, and what problems they’re trying to solve. The ideal outcome of this is that you’ll learn about new use cases to roll into your common and sanctioned designed patterns and templates.
Recommendation 3: Blocking, and Redirecting to Allowed Services
Once you have a solid model of which web-based AI services you want to allow, and which you want to block, you should feel empowered to begin doing so. Many organizations will take a first half-step of warning users, but still allowing access for a period of time. This can be tied into your user listening activities, by, for example, directing users to an access request form so that you can follow up on and debate justification for access to a currently blocked system.
It’s important to not just block access, but to have an allowed (sanctioned) web-based AI service to redirect users to. A message of “you can’t use service ABC, but instead use this comparable and supported service DEF” will be much more well-received. In many cases, you’re going to want to redirect people to an enterprise-managed tier within one of those services. We’ll be analyzing that type of agent in our next article in this series.
Recommendation 4: Data Security
Finally, remember that user interaction with these services involves data – including uploaded files, prompts, and results returned from these agents. It’s imperative that you have the capability to examine both inbound and outbound data, to ensure that sensitive files and information are not being sent. At the very least, you should be able to warn users, and require them to acknowledge that they understand your Acceptable Use Policy. More advanced capabilities will inspect the uploaded files and data, or use data sensitivity tags attached to files.
Wrapping Up Part 1 (and looking ahead to part 2)
This was our first analysis of agentic AI systems, using our simple taxonomy. I’m happy with this first analysis, although I recognize we’ve only begun to tackle this area. And, this is already a 2,000+ word blog posting! We’ll be going through the rest of the agent types in the taxonomy in forthcoming articles, and assuredly adding and changing things as we go.
In the meantime, what do you think of this approach? Let us know in the comments area if you have any questions or suggestions.
Want to receive these articles automatically via email? Subscribe for free at our newsletter site, Absolute Zero Trust.